Predicting brain activity using Transformers
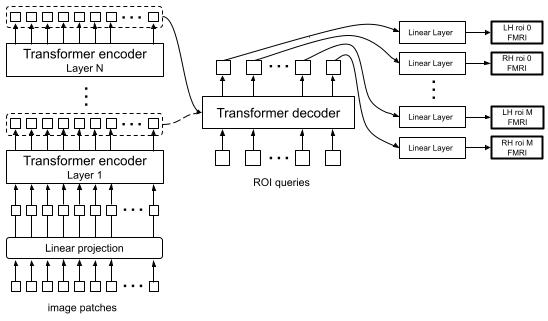
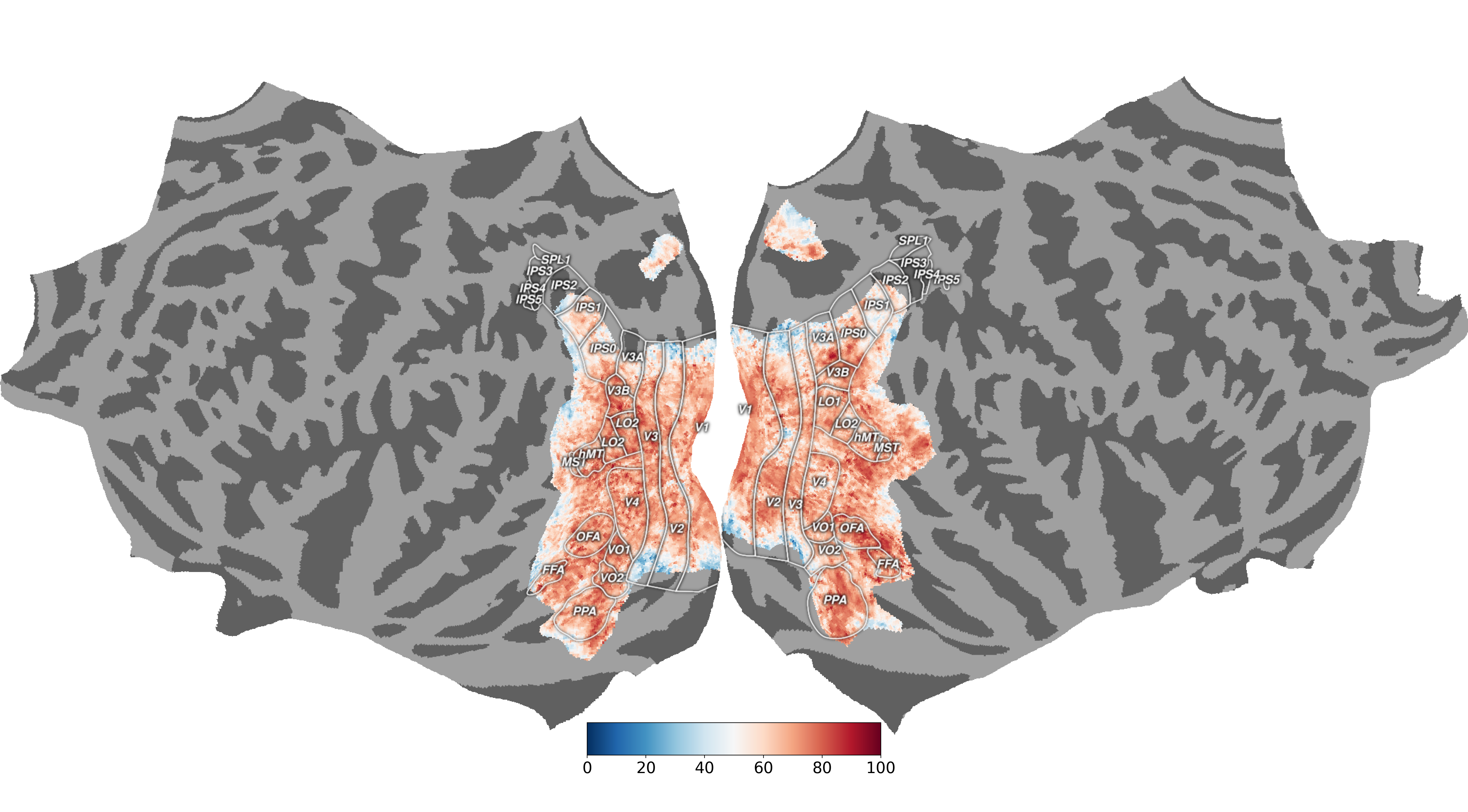
A major goal of computational neuroscience is to model how different brain regions respond to visual input. Our approach here leverages transformer neural networks for both the visual features and the mapping from features to brain responses. The image features are extracted from a powerful transformer model trained with self-supervision (DINOv2; Oquab et al. 2023) that can capture object-centric representations without labels (Adeli et al. 2023). The decoder uses queries corresponding to different brain regions of interests (ROI) in different hemispheres to gather relevant information from the encoder output for predicting neural activity in each ROI. The output tokens from the decoder are then linearly mapped to the fMRI activity. We trained different versions of our model with inputs to the decoder coming from different layers of the encoder and combined the responses for our final prediction. Our model was tested on a held-out set of the NSD dataset (as part of the Algonauts2023 challenge; Gifford et al. 2023) and achieved a score of 63.5 on the challenge ROIs.
Grouping and Object-based attention
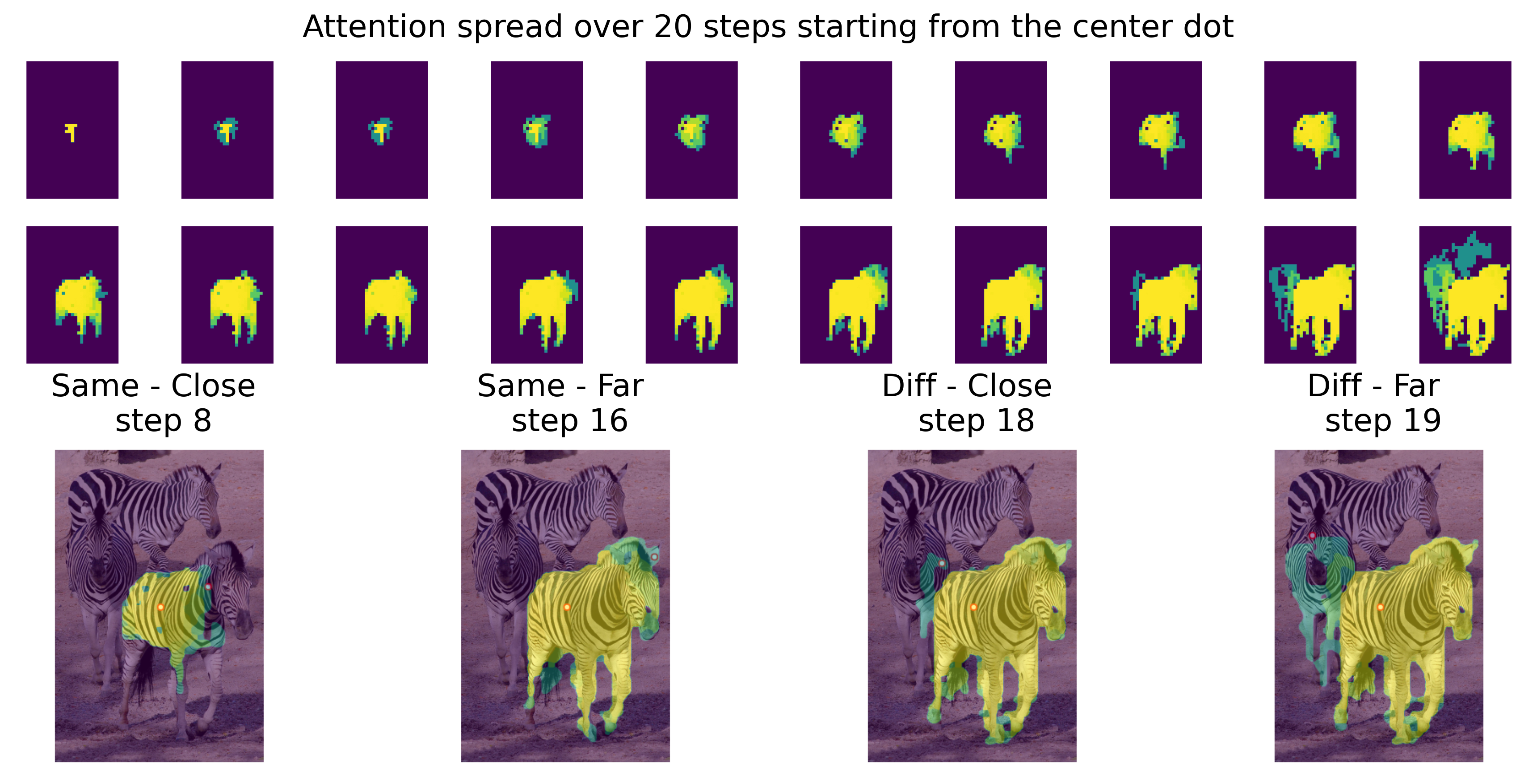
A fundamental problem that our visual system must solve is how to group parts of the visual input together into coherent whole objects.
Sequential glimpse attention for multiobject recognition and visual reasoning
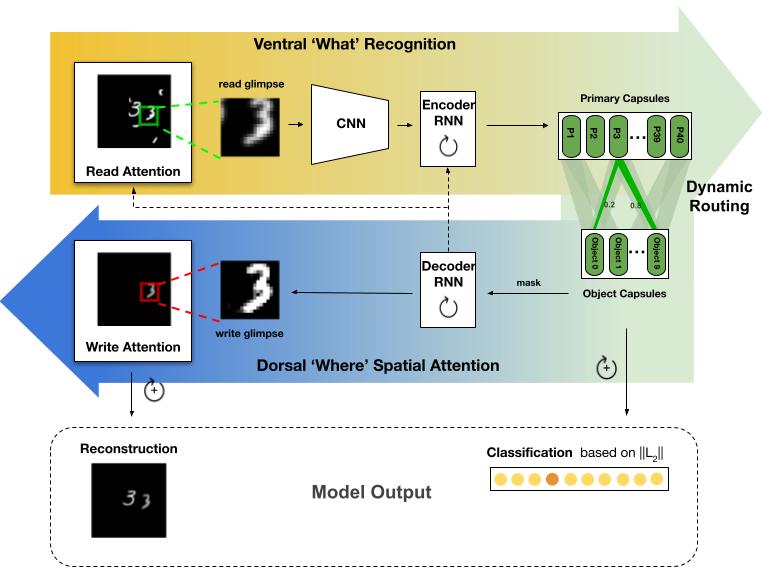


The visual system uses sequences of selective glimpses to objects to support goal-directed behavior, but how is this attention control learned? Here we present an encoder–decoder model inspired by the interacting bottom-up and top-down visual pathways making up the recognition-attention system in the brain. At every iteration, a new glimpse is taken from the image and is processed through the “what” encoder, a hierarchy of feedforward, recurrent, and capsule layers, to obtain an object-centric (object-file) representation. This representation feeds to the “where” decoder, where the evolving recurrent representation provides top-down attentional modulation to plan subsequent glimpses and impact routing in the encoder. We demonstrate how the attention mechanism significantly improves the accuracy of classifying highly overlapping digits. In a visual reasoning task requiring comparison of two objects, our model achieves near-perfect accuracy and significantly outperforms larger models in generalizing to unseen stimuli. Our work demonstrates the benefits of object-based attention mechanisms taking sequential glimpses of objects.
- Adeli, H., Ahn, S., & Zelinsky, G. J. (2023). A brain-inspired object-based attention network for multiobject recognition and visual reasoning. Journal of Vision, 23(5), 16-16. link/ github
A Computational Model of Attention in the Superior Colliculus


Modern image-based models of search prioritize fixation locations using target maps that capture visual evidence for a target goal. But while many such models are biologically plausible, none have looked to the oculomotor system for design inspiration or parameter specification. These models also focus disproportionately on specific target exemplars, ignoring the fact that many important targets are categories (e.g., weapons, tumors). We introduce MASC, a Model of Attention in the Superior Colliculus (SC). MASC differs from other image-based models in that it is grounded in the neurophysiology of the SC, a mid-brain structure implicated in programming saccades—the behaviors to be predicted. It first creates a target map in one of two ways: by comparing a target image to objects in a search display (exemplar search), or by using a SVM-classifier trained on the target category to estimate the probability of search display objects being target category members (categorical search).
- Adeli, H., Vitu, F., & Zelinsky, G. J. (2017). A model of the superior colliculus predicts fixation locations during scene viewing and visual search. Journal of Neuroscience, 37(6), 1453-1467.
- Vitu, F., Casteau, S., Adeli, H., Zelinsky, G. J., & Castet, E. (2017). The magnification factor accounts for the greater hypometria and imprecision of larger saccades: Evidence from a parametric human-behavioral study. Journal of Vision, 17(4):2, 1–38. [link][PDF]